 Mit Enterprise Search ist die unternehmensweite, inhalts-relevante Suche gemeint. Computergestützt und unter Zuhilfenahme einer Suchmaschine, die üblicherweise unternehmensintern gebunden ist, wird der gesuchte Content aufgelistet. Dabei findet die Suche jedoch nicht direkt auf den Datenquellen statt, sondern läuft über den Suchindex, der vor allem interne Daten bzw. Datenquellen beinhaltet. Zu diesen Daten gehören beispielsweise Datenbanken sowie Eintragungen in Dateisystemen. Aus der Perspektive der Unternehmen besteht der Zweck von Enterprise Search in der zielorientierten Unterstützung bei der Suche nach Informationen, die für die Arbeit der Mitarbeiter wichtig sind.
Mit Enterprise Search ist die unternehmensweite, inhalts-relevante Suche gemeint. Computergestützt und unter Zuhilfenahme einer Suchmaschine, die üblicherweise unternehmensintern gebunden ist, wird der gesuchte Content aufgelistet. Dabei findet die Suche jedoch nicht direkt auf den Datenquellen statt, sondern läuft über den Suchindex, der vor allem interne Daten bzw. Datenquellen beinhaltet. Zu diesen Daten gehören beispielsweise Datenbanken sowie Eintragungen in Dateisystemen. Aus der Perspektive der Unternehmen besteht der Zweck von Enterprise Search in der zielorientierten Unterstützung bei der Suche nach Informationen, die für die Arbeit der Mitarbeiter wichtig sind.
Die von Enterprise Search gefundenen Dateien werden im Anschluss an die Suchanfrage in Form von Textauszügen aufgeführt. Auf diese Weise wird schnell deutlich, wie relevant die Resultate tatsächlich sind. Außerdem lässt sich die Indexierung entsprechend einstellen, sodass die einzelnen Quellen nach Aktualität sortiert sind, was ebenfalls die schnelle Erkennung vereinfacht.
Die Relevanz von Enterprise Search
Durch die enorme Größe einiger Unternehmen bzw. Organisationen ist nicht immer erkennbar, wie effizient das gebündelte Wissen ist und wo es genau zu finden ist. Gerade bei international agierenden Unternehmen kommt es auf eine optimale Vernetzung an, damit die Zusammenarbeit gut funktioniert. Dies wird unter anderem durch ein firmeninternes Wissensmanagement ermöglicht, doch auch ein schnelles Auffinden von Informationen gehört dazu. Eine hochwertige und intelligente Software für Enterprise Search spielt somit eine wichtige Rolle, denn diese spart Zeit und Kosten.
Die Funktionsweise von Enterprise Search und anderen Suchmaschinen
Üblicherweise bestehen Suchmaschinen aus drei Komponenten: dem Crawling oder Indexing Engine, dem Query Engine und dem Ranging oder Relevancy Engine. Der Crawling bzw. Indexing Engine beschafft die Daten und Dokumente aus den Datenquellen und führt sie anschließend entsprechend in einer Struktur auf, die wiederum die Suche vereinfacht. Gleichzeitig erstellt der Crawling Engine Caches der Dokumente, damit eine Dokumentvorschau dargestellt werden kann. Dieser Index wird von dem Query Engine durchlaufen, um die Treffer aufzulisten. Daraufhin sortiert der Ranking oder Relevancy Engine die Treffer in der gewünschten Reihenfolge. Die Oberfläche wird zumeist durch einen Webbrowser dargestellt, sodass die Suchergebnisse ähnlich wie bei Internet Search Engines aufgeführt werden.
Komponenten
Das Backend ist eine der Hauptkomponenten von Enterprise Search und beinhaltet zunächst die verwendeten Konnektoren sowie den Crawler, den Indexer und die Parser, die für die Suchanfragen erforderlich sind, die von den einzelnen Frontends kommen. Die Suchanfragen werden weitergeleitet, damit die tatsächliche Suchmaschine die Daten aus der aufgelisteten Datenbank zieht. Das einzelne Frontend kann aus einem einfachen Eingabefeld bestehen oder weitere Anzeigen beinhalten wie die Anzeige von verwandten Suchobjekten oder Navigationshilfen. Je weiter die Treffer durch Begriffe oder Kriterien eingeschränkt werden, desto eindeutiger sind die Resultate. Das Frontend ist üblicherweise auch für die Formatierung der Ergebnisse zuständig, ebenso für komfortable Bedien-, Speicher- und/oder Suchfunktionen.
Erforderliche Schnittstellen für Enterprise Search
Die meisten Anbieter von Enterprise Search setzen auf Adaptoren oder auch Konnektoren, die ein Unternehmensprogramm unterstützen, sodass die gesuchten Inhalte in den Ergebnissen angezeigt werden können. Eine Kundendatenbank kann beispielsweise direkt abgefragt werden, Plugins ermöglichen die Einbindung von E-Mail-Programmen für festgelegte Gruppen, und Content- und Dokumenten-Managementsysteme können ebenso verbunden werden. Eigene Netzlaufwerke und Filesysteme sind eine weitere Möglichkeit für die Verbindung der Arbeitsplätze und Gruppen. Teilweise werden auch Konnektoren für Federated Search verwendet, durch die eine Suchabfrage an das entsprechende Zielsystem weitergeleitet wird.
Der effektive Einsatz von Suchmaschinen
Datenbanken dienen im ursprünglichen Sinne der Verwaltung von strukturierten Inhalten. Im Gegensatz dazu unterstützen Suchmaschinen und die Erschließung von Inhalten, die nicht notwendigerweise strukturiert sein müssen. Unstrukturierte Inhalte werden ebenso durchsucht und aufgelistet. Ein weiterer Unterschied zwischen Datenbanken und Suchmaschinen zeigt sich bei der Menge der zu durchsuchenden Datenquellen. Während bei einer Datenbank zumeist nur eine einzelne Quelle durchsucht wird, kann Enterprise Search in mehreren Quellen gleichzeitig suchen. Außerdem erfordert eine Abfrage in der Datenbank eine spezielle Sprache, beispielsweise SQL, während sich die Abfragesprache bei Enterprise Search sehr viel einfacher gestaltet. Der große Vorteil von Suchmaschinen liegt vor allem in der Schnelligkeit, denn die Abfrage benötigt normalerweise nicht länger als eine Sekunde. Im Vergleich dazu dauert eine Datenbankabfrage manchmal mehrere Stunden.
Ein Blick in die Zukunft
In der Studie „The Diverse and Exploding Digital Universe“, durchgeführt von den Marktforschern von IDC, wurde ein extremer Anstieg der Menge an digitalen Informationen sowie der Format-Varianten prognostiziert. Die IT-Abteilungen in den Unternehmen und Organisationen sind für die enorme Datenmenge verantwortlich, was ihre Aufgabe sehr komplex macht. Speichern, Bereitstellen, Übermitteln und Datenschutz, das alles liegt in den Händen der IT-Manager, die immer näher an ihre Grenzen kommen. Daher setzen die Unternehmen vermehrt auf einheitliche und zentralisierte Systeme, die die Datenverwaltung optimieren sollen. Die üblicherweise verwendeten DMS-Lösungen sind jedoch nicht dazu konzipiert, die enormen Mengen an Daten zu verwalten. In der Folge fällt es den Mitarbeitern immer schwerer, die gesuchten Informationen zu finden. Das Verwalten, Suchen und Auffinden von Informationen – also das Wissensmanagement – wird dadurch zu einem relevanten Thema gerade für die großen Unternehmen.
Die IT-Sicherheit spielt ebenfalls eine wichtige Rolle, denn häufig sind es gerade die kostenlos verfügbaren Suchmaschinen, die Lücken aufweisen. Diese Programme erstellen teilweise ein Inhaltsverzeichnis, das wiederum in Berichtform von den Suchmaschinen in das externe Umfeld übertragen wird. Die Datenschutzrichtlinien werden dadurch gefährdet, auch wenn persönliche Daten angeblich sicher sind. Im Gegensatz dazu halten Enterprise Search Lösungen die sicherheitsrelevanten Vorgaben ein, da sie komplett intern arbeiten und das Risikopotential entsprechend minimieren.
In den USA haben bereits einige effektive Enterprise Search Lösungen auf den Markt Fuß gefasst, . Eine Verbesserung des Datenschutzes mit seinen Richtlinien gehört ebenso mit dazu wie eine politische Unterstützung der Forschung und Entwicklung in diesem Bereich.

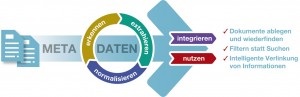 Gerade im Bereich der Enterprise Search ist es für Unternehmen essentiell wichtig, unternehmensweite Daten richtig strukturieren zu können, um sie für den Suchenden schnell und unkompliziert auffindbar zu machen. Hierbei dient der Tagging Service, welcher bspw. als Ergänzung zu einer bestehenden Enterprise Search-Lösung wie dem IntraFind iFinder angeboten wird, als Möglichkeit, über Metadaten Inhalte richtig beschreiben zu können, sprich sie zu verschlagworten.
Gerade im Bereich der Enterprise Search ist es für Unternehmen essentiell wichtig, unternehmensweite Daten richtig strukturieren zu können, um sie für den Suchenden schnell und unkompliziert auffindbar zu machen. Hierbei dient der Tagging Service, welcher bspw. als Ergänzung zu einer bestehenden Enterprise Search-Lösung wie dem IntraFind iFinder angeboten wird, als Möglichkeit, über Metadaten Inhalte richtig beschreiben zu können, sprich sie zu verschlagworten. Die Welt ist digital – und das jeden Tag ein bisschen mehr. Unternehmen, Behörden und Organisationen sind auf Computer, Systeme und Programme angewiesen, mit denen sie ihre digitalen Daten und Dokumente verwalten können. Im Grunde stellt dies eine Arbeitserleichterung zur papierlastigen Arbeitsweise in früheren Zeiten dar, allerdings ist es auch Fakt, dass das in Unternehmen vorhandene Datenvolumen stetig wächst. Schnell entstehen folglich Probleme, wenn wichtige Dateien nicht mehr oder nicht rechtzeitig gefunden werden – ein Zeit- und Kostenaufwand, der für Unternehmen schnell zum Wettbewerbsnachteil werden und viel Geld kosten kann.
Die Welt ist digital – und das jeden Tag ein bisschen mehr. Unternehmen, Behörden und Organisationen sind auf Computer, Systeme und Programme angewiesen, mit denen sie ihre digitalen Daten und Dokumente verwalten können. Im Grunde stellt dies eine Arbeitserleichterung zur papierlastigen Arbeitsweise in früheren Zeiten dar, allerdings ist es auch Fakt, dass das in Unternehmen vorhandene Datenvolumen stetig wächst. Schnell entstehen folglich Probleme, wenn wichtige Dateien nicht mehr oder nicht rechtzeitig gefunden werden – ein Zeit- und Kostenaufwand, der für Unternehmen schnell zum Wettbewerbsnachteil werden und viel Geld kosten kann. Große Datenmengen, diverse Speichersysteme und Ablageorte, Zeitdruck und wo war noch gleich das Protokoll des letzten Projektmeetings in der aktuellsten Version?
Große Datenmengen, diverse Speichersysteme und Ablageorte, Zeitdruck und wo war noch gleich das Protokoll des letzten Projektmeetings in der aktuellsten Version? Für die automatische Verschlagwortung kursieren unterschiedlichste Begrifflichkeiten: Metadaten, Schlagworte, Keywords, Tags, Tagging – all diese Begriffe stehen in einem Zusammenhang. Und was waren noch mal Entitäten? Wofür brauche ich eine automatische Verschlagwortung in meinem Unternehmen?
Für die automatische Verschlagwortung kursieren unterschiedlichste Begrifflichkeiten: Metadaten, Schlagworte, Keywords, Tags, Tagging – all diese Begriffe stehen in einem Zusammenhang. Und was waren noch mal Entitäten? Wofür brauche ich eine automatische Verschlagwortung in meinem Unternehmen? Eine schnell nutzbare Suchlösung für Internet- oder Intranetseiten – mit diesem Ansatz baute Google vor Jahren eine Appliance namens Google Mini und richtete sich mit dem Angebot der internen Unternehmenssuche an das klassische KMU Segment. Seit Juli 2012 nun bietet Google diese Appliance nicht mehr an. Support wird aktiv nicht mehr angeboten, „Hilfe“ erhält man nur noch über Foren und die Google-eigene Hilfeseite. Zahlreiche mittelständische Kunden suchen nun nach Alternativen.
Eine schnell nutzbare Suchlösung für Internet- oder Intranetseiten – mit diesem Ansatz baute Google vor Jahren eine Appliance namens Google Mini und richtete sich mit dem Angebot der internen Unternehmenssuche an das klassische KMU Segment. Seit Juli 2012 nun bietet Google diese Appliance nicht mehr an. Support wird aktiv nicht mehr angeboten, „Hilfe“ erhält man nur noch über Foren und die Google-eigene Hilfeseite. Zahlreiche mittelständische Kunden suchen nun nach Alternativen. Das erste Mal, als ich über Big Data nachdachte, kannte ich diesen Begriff noch gar nicht. Ich fragte mich lediglich, wie Unternehmen in der Zukunft mit der enormen stetig anwachsenden Datenmenge zurechtkommen und wie Mitarbeiter relevante Informationen aus dem Überfluss an Quellen noch entschlüsseln sollen?
Das erste Mal, als ich über Big Data nachdachte, kannte ich diesen Begriff noch gar nicht. Ich fragte mich lediglich, wie Unternehmen in der Zukunft mit der enormen stetig anwachsenden Datenmenge zurechtkommen und wie Mitarbeiter relevante Informationen aus dem Überfluss an Quellen noch entschlüsseln sollen?